Cours - combiner des commandes Linux - redirections et pipes
redirections et assemblages
Schema fonctionnel d'une commande
- Une commande est une boîte avec des entrées / sorties
- et un code de retour (
$?)- 0 : tout s'est bien passé
- 1 (ou toute valeur différente de 0) : problème !
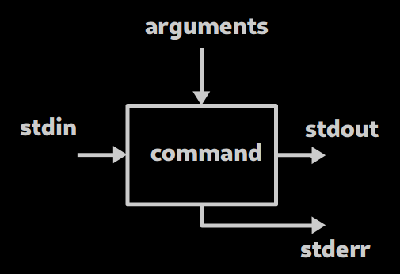
Entrées / sorties
- arguments : donnés lors du lancement de la commande (ex:
/usr/dansls /usr/) - stdin : flux d'entrée (typ. viens du clavier)
- stdout : flux de sortie (typ. vers le terminal)
- stderr : flux d'erreur (typ. vers le terminal aussi !)
Code de retour !
$ ls /toto
ls: cannot access '/toto': No such file or directory
$ echo $?
2
Rediriger les entrées/sorties
cmd > fichier: renvoie stdout vers un fichier (le fichier sera d'abord écrasé !)cmd >> fichier: ajoute stdout à la suite du fichiercmd < fichier: utiliser 'fichier' comme stdin pour la commandecmd <<< "chaine": utiliser 'chaine" comme stdin pour la commande
Exemples
ls -la ~/ > tous_mes_fichiers.txt # Sauvegarde la liste de tous les fichiers dans le home
echo "manger" >> todo.txt # Ajoute "manger" a la liste des choses à faire
wc <<< "une grande phrase" # Compte le nomde de mot d'une chaine
commande 2> fichier: renvoie stderr vers un fichier (le fichier sera d'abord écrasé !)commande 2>&1: renvoie stderr vers stdout !commande &> fichier: renvoie stderr et stdout vers un fichier (le fichier sera d'abord écrasé !)
Exemples :
ls /* 2> errors # Sauvegarde les erreurs dans 'errors'
ls /* 2>&1 > log # Redirige les erreurs vers stdout (la console) et stdout vers 'log'
ls /* > log 2>&1 # Redirige tout vers 'log' !
ls /* &> log # Redirige tout vers 'log' !
Fichiers speciaux :
/dev/null: puit sans fond (trou noir)/dev/urandom: generateur aleatoire (trou blanc)

ls /* 2> /dev/null # Ignore stderr
mv ./todo.txt /dev/null # Façon originale de supprimer un fichier !
head -c 5 < /dev/urandom # Affiche 5 caractères de /dev/urandom
cat /dev/urandom > /dev/null # Injecte de l'aleatoire dans le puit sans fond
Assembler des commandes
Executer plusieurs commandes à la suite :
cmd1; cmd2: executecmd1puiscmd2cmd1 && cmd2: executecmd1puiscmd2mais seulement sicmd1reussie !cmd1 || cmd2: executecmd1puiscmd2mais seulement sicmd1a échouécmd1 && { cmd2; cmd3; }: "groupe"cmd2etcmd3ensemble (attention à la syntaxe !!)
Que fait cmd1 && cmd2 || cmd3 ?
Essayons:
echo "1" && echo "2" || echo "3"echo "1" && wget site-inexistant.fr || echo "3"wget site-inexistant.fr && echo "2" || echo "3"
pipes et outils
Pipes !
cmd1 | cmd2permet d'assembler des commandes de sorte à ce que lestdoutdecmd1devienne lestdindecmd2!
Exemple : cat /etc/login.defs | head -n 3
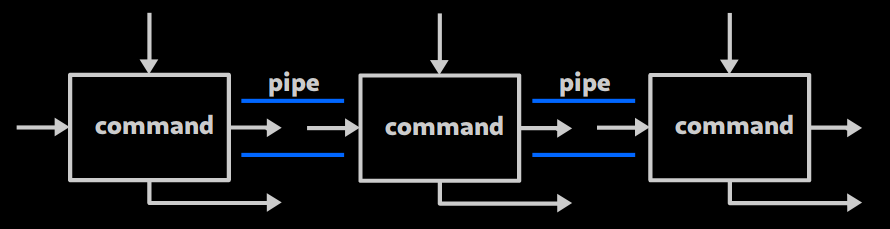
- (Attention, par défaut
stderrn'est pas affecté par les pipes !)
Lorsqu'on utilise des pipes, c'est generalement pour enchaîner des opérations comme :
- générer ou récupérer des données
- filtrer ces données
- modifier ces données à la volée
Sous Linux : tout est fichier / tout est flux de texte
Precisions techniques
- La transmission d'une commande à l'autre se fait "en temps réel". La première commande n'a pas besoin d'être terminée pour que la deuxieme commence à travailler.
- Si la deuxieme commande a terminée, la première peut être terminée prématurément (SIGPIPE).
- C'est le cas par exemple pour
cat tres_gros_fichier | head -n 3
- C'est le cas par exemple pour
Boîte à outils : tee
tee permet de rediriger stdout vers un fichier tout en l'affichant quand meme dans la console
tree ~/documents | tee arbo_docs.txt # Affiche et enregistre l'arborescence de ~/documents
openssl speed | tee -a tests.log # Affiche et ajoute la sortie de openssl à la suite de tests.log
Boîte à outils : grep
grep permet de trouver des lignes qui contiennent un mot clef (ou plus generalement, une expression)
$ ls -l | grep r2d2
-rw-r--r-- 1 alex alex 0 Oct 2 20:31 r2d2.conf
-rw-r--r-- 1 r2d2 alex 1219 Jan 6 2018 zblorf.scd
$ cat /etc/login.defs | grep TIMEOUT
LOGIN_TIMEOUT 60
(on aurait aussi pu simplement faire : grep TIMEOUT /etc/login.defs)
Une option utile (parmis d'autres) : -v permet d'inverser le filtre
$ ls -l | grep -v "alex alex"
total 158376
d---rwxr-x 2 alex droid 4096 Oct 2 15:48 droidplace
-rw-r--r-- 1 r2d2 alex 1219 Jan 6 2018 zblorf.scd
On peut créer un "ou" avec : r2d2\|c3p0
$ ps -ef | grep "alex\|r2d2"
## Affiche seulement les lignes contenant alex ou r2d2
On peut faire référence à des débuts ou fin de ligne avec ^ et $ :
$ cat /etc/os-release | grep "^ID"
ID=manjaro
$ ps -ef | grep "bash$"
alex 5411 956 0 Oct02 pts/13 00:00:00 -bash
alex 5794 956 0 Oct02 pts/14 00:00:00 -bash
alex 6164 956 0 Oct02 pts/15 00:00:00 -bash
root 6222 6218 0 Oct02 pts/15 00:00:00 bash
Boîte à outils : tr
tr ('translate') traduit des caractères d'un ensemble par des caractère d'un autre ensemble ...
$ cat /etc/os-release \
| grep "^ID" \
| tr '=' ' '
ID manjaro
$ echo "coucou" | tr 'a-q' 'A-Q'
COuCOu
Boîte à outils : awk
awk est un processeur de texte assez puissant ...
- En pratique, il est souvent utilisé pour "récupérer seulement une ou plusieurs colonnes"
- Attention à la syntaxe un peu compliquée !
$ cat /etc/os-release \
| grep "^ID" \
| tr '=' ' ' \
| awk '{print $2}' \
manjaro
$ who | awk '{print $1 " " $4}'
alex 22:10
r2d2 11:27
- L'option
-Fpermet de specifier un autre délimiteur
cat /etc/passwd | awk -F: '{print $3}' # Affiche les UID des utilisateurs
(Equivalent à cat /etc/passwd | cut -d: -f 3)
plus sur awk : https://www.funix.org/fr/unix/awk.htm
Boîte à outils : sort
sort est un outil de tri :
-kpermet de spécifier quel colonne utiliser pour trier (par défaut : la 1ère)-npermet de trier par ordre numérique (par défaut : ordre alphabetique)
ps -ef | sort # Trie les processus par proprietaire (1ere col)
ps -ef | sort -k2 -n # Trie les processus par PID (2eme col., chiffres)
viddy 'ps -ef | sort -k2 -n'
Boîte à outils : uniq
uniq permet de ne garder que des occurences uniques ... ou de compter un nombre d'occurence (avec -c)
uniq s'utilise 90% du temps sur des données déjà triées par sort
who | awk '{print $1}' | sort | uniq # Affiche la liste des users loggués
who | awk '{print $1}' | sort | uniq -c # Compte le nombre de shell par user loggué
Boîte à outils : sed
sed est un outil de manipulation de texte très puissant ... mais sa syntaxe est complexe.
Comme premier contact : utilisation pour chercher et remplacer : s/motif/remplacement/g
Exemple :
ls -l | sed 's/alex/padawan/g' # Remplace toutes les occurences de alex par padawan
Boîte à outils : find
find permet de trouver (recursivement) des fichiers répondant à des critères sur le nom, la date de modif, la taille, ...
Il permet aussi d'exécuter automatiquement une commande pour chaque fichier trouvé.
Exemples:
## Lister tous les fichiers en .service dans /etc
find /etc -name "*.service"
## Lister tous les fichiers dans /var/log modifiés il y a moins de 5 minutes
find /var/log -mmin 5
## Cherche les 3 fichier .wav de r2d2 et affiche des information sur leur type
find /home/r2d2 -iname "*.wav" -exec file {} \;
Plus sur find en combinaison avec awk : https://www.baeldung.com/linux/find-exec-command
Recap (QUELQUES outils)
(en tout cas leur utilisation la plus commune)
tee: montrer la sortie dans le terminal tout en la copiant dans un fichiertr: supprimer / remplacer certains caractèresgrep: garder seulement les lignes qui matchent (ou pas) une expressionawk: garder seulement une colonne de donnéecut: garder seulement une colonne de donnée (similaire àawkmais différent)sort: trier des donnéesuniq: garder seulement des lignes uniques (ou compter combien d'occurences)sed: chercher et remplacer une expression par une autrefind: chercher des fichiers qui correspondent à certains critères (nom, date de modif, ...)